KI-Stimmerkennung: Die perfekte Podcast-Stimme
Podcasts sind auf einem medialen Siegeszug – keine Frage. Und nicht nur auf der Creator-Seite befindet sich die mediale Entwicklung auf dem Vormarsch.
Mit PodMon konzentrieren wir uns aktuell darauf, unsere KI-Infrastruktur zu optimieren und vor allem den autonomen Lernprozess unseres Tools weiterzuentwickeln. Neben der Identifikation von Themen in Podcasts haben wir natürlich noch weitere – eher experimentelle Themen, die wir im Bereich Computer-Sprachverstehen vorantreiben.
Wir beschäftigen uns dabei u.a. mit dem Thema KI-Stimmerkennung und Speech-to-Text Analysen. In der KI-Forschung wird der Markt nach wie vor besonders von US-Anbietern dominiert. Die Entwicklung von adäquaten Sprachmodellen speziell in Deutschland steckt daher noch voller Herausforderungen. Mit GPT-X gibt es endlich auch ein europäisches Projekt, das hoffentlich bald ein wenig mehr EU-Haftigkeit in die KI-Welt bringt. Einer der ersten Nutzer des Modells ist der WDR. Die Abteilung Informationsmanagement testet, wie gut GPT-X auch lange Texte versteht, so bspw. Transkripte aus Podcasts. Zukünftige Anwendungsgebiete wären dann unter anderem das Verfassen von kurzen Inhaltsangaben für die Mediathek. In Sachen europäische KI-Initiativen bleibt es also spannend…
Für uns wird es an dieser Stelle ebenso Zeit, ein paar Insights zu geben, was hier hinter den Kulissen Spannendes in Sachen Audio-Analyse passiert.
Im Kontext von Podcasts gibt es unzählige Use-Cases, die perspektivisch auch für PodMon relevant werden könnten. Denkbar sind die Entwicklung eigener automatisierter KI-Podcast-Sprecher in Kombination mit automatischen Themen-Kuratoren, Speaker- und Voice-Analysen zur Erforschung von Werbewirkung, aus denen ein Matching-Algorithmus die beste Paarung von Sprecher, Themen und Marken-Platzierung ermitteln kann. Spannende Themen gibt es viele!
So stellen wir uns mehr und mehr die Frage, was macht die Stimme aus, was schafft Vertrauen, welche Themen passen zu welcher Stimme, wie wird Emotion über die Stimme transportierbar? Und wie kann das Ganze messbar gemacht werden? Aber bevor es zu philosophisch wird – hier ein kleiner Einblick in unsere Experimente auf dem Weg zum eigenen KI-Podcast.
Im Durchschnitt erzeugen Männer mit ihrer Stimme einen Grundton von ca. 125 Hertz. Frauen, deren Stimmlippen in etwa ein Viertel kürzer sind, erreichen durchschnittlich 200 Hertz. Bei Kindern beträgt die Stimmfrequenz ca. 400 Hertz. Darüber hinaus hat jede Stimme ihre eigenen Frequenzbereiche, in die sie aufgeteilt werden kann. Je nach Umgebung und Sprech-Kontext kann das „Farbspektrum“ variieren, daher müssen Stimmanalysen möglichst in vielen Situationen und Facetten gelernt werden.
Wichtig ist, diese Analysen mittels KI-Stimmerkennung möglichst aus unterschiedlichen Situationen heraus zu erfassen und daraus die Schnittmenge – also das Meta-Bild des Stimmprofils zu erstellen. Erst dann wird es aus dem Aufnahmekontext herauslösbar und mit anderen Stimmbildern vergleichbar.
Resultat sind einzigartige Frequenz-Spektren, die es erlauben, den stimmlichen Fingerabdruck visuell zu zeigen:
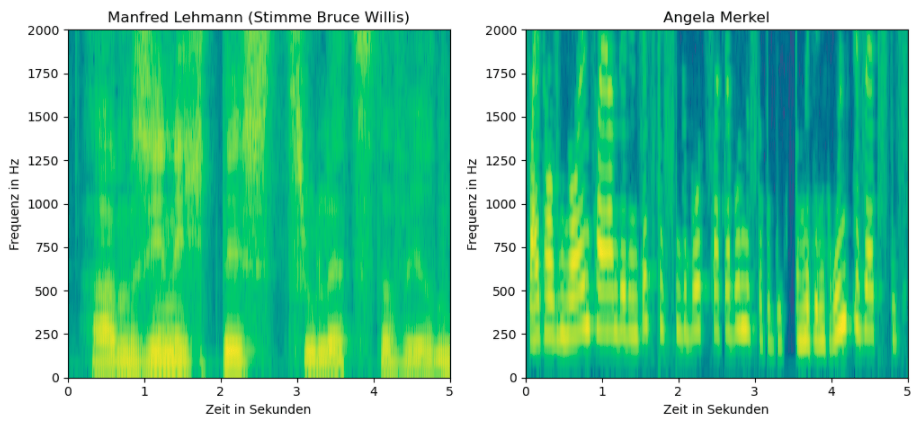
Was sieht man? Die Spektogramme zeigen, dass die Stimmen sehr gut unterscheidbar und mit Hilfe von KI-Methoden auch auf detaillierter Ebene sehr klar differenzierbar sind. Die gelbliche Farbe gibt dabei die stärkere Ausprägung eines Frequenzbereichs an.
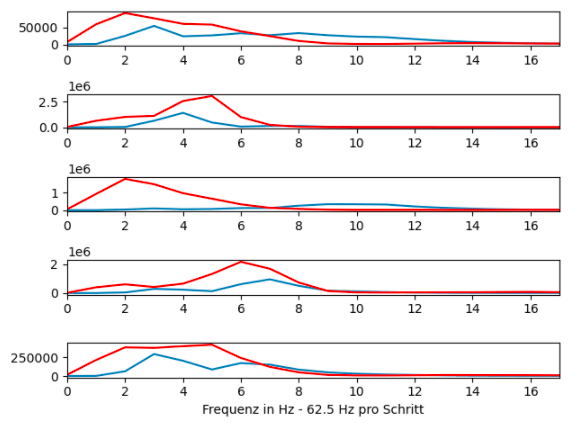
Die Analyse mehrerer solcher Spektogramme einer Person ermöglicht es, die typischen Klänge dieser zu visualisieren. Die Ergebnisse dieser sogenannten kmeans Cluster von Angela Merkel und Manfred Lehmann haben wir hier dargestellt. Es sei dazu gesagt, dass diese Methode einen ersten Überblick über den Datenraum der typischen Klänge ermöglicht und sich hierbei als nächster Schritt eine Analyse mittels MFCCs anbietet, welche eine Dimensionsreduktion der verschiedenen Frequenzen darstellt und eine gleichmäßigere Verteilung über alle Dimensionen des Vektors ermöglicht.
Die oben erklärte Erschließung des Datenraums bei der Voice-Analyse kann man zunächst einmal die Basisarbeit bezeichnen – denn es ermöglicht uns, Stimmprofile vergleichbar zu machen. Neben der eingangs erwähnten Use-Cases für PodMon im Kontext von Themen und Voice-Analysen stehen hier vielfältige Anwendungsbereiche zur Verfügung, an denen wiederum auf vielen Seiten reichlich geforscht wird:
Britische Wissenschaftler haben tatsächlich eine Formel für die perfekte Stimme entwickelt. Ob du damit gesegnet bist, kannst du also ganz einfach über ([164,2wpm x 0,48pbs]) Fi = PVQ herausfinden. Demnach zeichnet sich die ideale Stimme durch weniger als 164 Wörter pro Minute (wpm) und einer Pause von 0,48 Sekunden (pbs) nach jedem Satz aus. Zum Ende des Satzes sollte die Satzmelodie zudem abfallen (Fi).
Neben der Mathematik und Technologie gibt’s natürlich noch einige nicht wirklich mathematisch beschreibbare Faktoren, die das echte Handwerk betreffen. Beispielsweise spielt es natürlich eine wichtige Rolle, ob Content und speziell Audio-Themen vom Hörer wohlwollend oder abgeneigt erfahren werden. Einfach gesagt: Wenn viele Hörer:innen schon innerhalb der Episode wegklicken, gefällt ihnen entweder das besprochene Thema nicht (Inhalt) oder die Stimme oder eben die Umsetzung des Themas durch den Podcast-Host wird als unattraktiv empfunden. Insbesondere die Attraktivität der Stimme und die professionelle Aufbereitung des Podcasts sowohl aus inhaltlicher als auch aus produktionstechnischer Sicht lassen sich als wichtige Kriterien sehen, ob User einem Podcast folgen und regelmäßig einschalten.
Und hier gibt es mittlerweile einige Profis, die jungen Creators dabei helfen, sich für eine Karriere als Podcaster perfekt auszustellen. Dort bekommst du z.B. Tipps, wie du an deiner Stimme arbeiten kannst (auch ganz ohne mathematische Formel). Und Journalisten helfen dabei, Themen podcast-gerecht aufzubereiten. So rät Gesangs-, Stimm- und Sprechtrainerin Angela Kiemayer bspw. die Stimme vor jeder Episode aufzuwärmen; am besten geht das durch Summen. Deutliche Verbesserungen lassen sich aber auch durch die richtige Ernährung und Haltung während der Podcast-Aufzeichnung erzielen.
Die perfekte (Podcast) Stimme ist also von vielen verschiedenen Faktoren abhängig. KI-Stimmerkennung macht sie darstellbar. Bis komplette Podcasts unterhaltsam von Künstlichen Intelligenzen geführt werden, wird wohl noch etwas Training nötig sein. Bis dahin kann mit den Tipps und Tricks von Angela Kiemayer jede:r selbst an der eigenen perfekten Stimme arbeiten.